
Detecting the Odd One Out: A Guide to One-Class Classification

Imagine a scenario where a security analyst monitors a high-value corporate network. One day, an anomaly disturbs the software process, which behaves unpredictably. The disturbance in software mimics normal operations but subtly deviates just enough to raise suspicion. No malware signatures match, and traditional classifiers fail to detect it. This highlights a common challenge in real-world anomaly detection spotting the “odd one out” in a sea of normal data. This is where One-Class Classifiers (OCCs) come in. These models are trained to deeply understand normal behavior, making anything abnormal stand out like a sore thumb.
In this blog, we’ll explore the concept of One-Class Classifiers (OCCs), how they work, when to use them, and their wide-ranging applications. From cybersecurity to healthcare and image analysis, OCCs are essential for identifying critical anomalies.
What is a One Class Classifier?
A One-Class Classifier (OCC) is a type of machine learning algorithm designed to identify whether a given data point belongs to the same distribution as the training data (normal class) or deviates from it (anomalous class). Unlike traditional classification models that require categories, OCC focuses solely on learning the characteristics of the “normal” class, which makes it good for finding anomalies.
How Does One Class Classifier Work?
A One-Class Classifier learns to encapsulate the boundaries of the normal data distribution during training. When presented with new data during inference, the model determines if it falls within this boundary (normal) or outside (anomalous). Popular algorithms for OCC include:
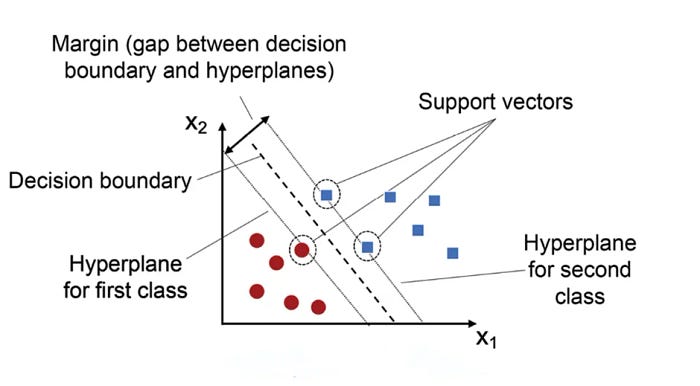
- One Class SVM (Support Vector Machine)- OCC SVM uses hyperplanes to separate normal data from potential anomalies.
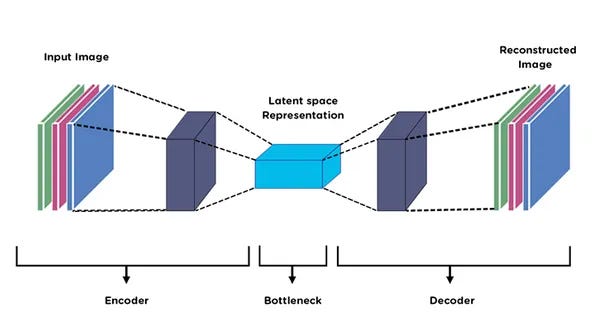
- Autoencoder- Neural networks trained to reconstruct input data were reconstructed error signal potential anomalies.
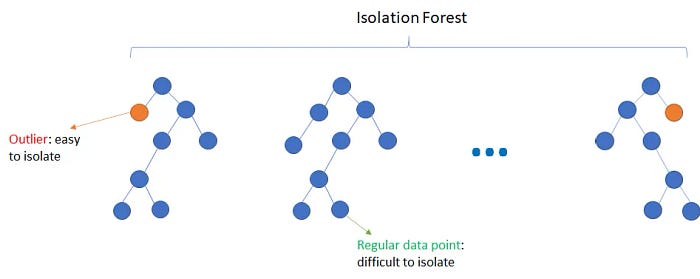
- Isolation Forest- It randomly splits data into trees to isolate anomalies, which tend to require fewer splits.
Why Choose a One-Class Classifier?
1 Limited Anomalous Data- In many applications, such as fraud detection or medical diagnosis, anomalous examples are scarce, making traditional classifiers ineffective.
2 The Dynamic Nature of Anomalies — Anomalies are often unpredictable and diverse, and explicitly labeling them during training is impractical.
3 Efficiency- OCC models are designed to focus on the normal class, simplifying the training process and making them suitable for real-time applications.
By mastering OCCs, you can tackle anomaly detection challenges in diverse domains, ranging from cybersecurity to predictive maintenance.
When should you use a Once-Class Classifier (OCC)?
One-Class Classifiers shine in scenarios where anomalies are too rare or unpredictable to model effectively. Some common OCCS use cases are as follows:

1 Cybersecurity- One-class classifiers are invaluable for anomaly detection systems in cybersecurity. They help identify unusual patterns or activities that could indicate a security breach, such as unusual network traffic, access patterns, or file activities, which deviate from the norm established by a system’s “normal” operational data.
2 Fraud Detection- Financial institutions use one-class classifiers to detect fraudulent transactions. Here, the model is trained on data representing normal transactions. It then flags transactions that deviate significantly from this norm as potential frauds. This is crucial because fraudulent techniques constantly evolve, and it may not always be feasible to have updated examples of every type of fraud.
3 Healthcare Diagnostics- Detecting abnormalities in medical imaging or patient data when healthy cases are well documented but anomalies are scarce.
4 Image Analysis- Differentiating between normal and manipulated images in computer vision tasks.
How do you recognize if a One-Class Classifier (OCC) is the right choice for your data?
For most people, the first question is how can we recognize if a One-Class Classifier is the right choice for data? An OCC is highly effective but is not always the best fit. Below are the ways to evaluate whether OCC is a good option for your data:

1 Imbalanced Datasets- If the dataset consists mostly of “normal” instances with very few or no labeled anomalies. OCC works best in this case, as OCC models only need normal data to train. Their design enables effective learning in datasets with significant class disparities.
- Example- Fraud detection in financial systems, where most transactions are legitimate, and fraudulent ones are rare.
2 Limited or No Anomalous Data- Examples are unavailable, hard to define, or insufficient for training a supervised model. By training exclusively on normal data, OCCs eliminate the need for labeled anomalies, making them a practical choice for many applications.
- Example: Industrial equipment monitoring, where failures are rare and unpredictable.
3 Dynamic or Undefined Anomalies: Anomalies do not follow a consistent pattern, and their nature changes over time. OCC works best as OCC models detect deviations from normal behavior, making them adaptable to new or unseen anomalies.
- Example: Network intrusion detection, where attackers constantly evolve their strategies.
4 Continuous or Real-Time Monitoring: Your application requires ongoing monitoring of data streams to identify unusual behavior. OCC works best here as OCC models are lightweight and efficient, enabling real-time anomaly detection.
- Example: Healthcare monitoring systems, where patient vitals must be analyzed in real-time.
5 Unlabeled or Partially Labeled Data: The dataset lacks labeled examples for anomalies, or labeling data is expensive and time-consuming. OCC works best here, bypassing the need for labeled anomaly data and saving time and resources.
- Example: Image analysis for detecting rare manufacturing defects.
Below are some questions you can ask yourself when choosing OCC; if you answered “yes” to most of these questions, a One-Class Classifier is likely a strong candidate for your problem:
Q1: Is the dataset predominantly normal, with rare or undefined anomalies?
Q2: Do you have limited or no labeled anomalous data?
Q3: Are anomalies diverse or unpredictable in nature?
Q4: Does your application require real-time or continuous anomaly detection?
Q5: Are the consequences of missing anomalies significant?
How to Implement a One-Class Classifier?
There are various ways to implement OCC. Let’s walk through an example of using a One-Class Support Vector Machine (SVM) to detect anomalies in a dataset. A step-by-step guide will help you understand the practical implementation of OCC.
Step 1 Prepare Your Data
Data preparation plays a vital role in OCC. Below are some guidelines you should consider when preparing data for OCC.
- Use only normal data for training and exclude anomalies.
- Normalize or scale features using techniques like Min-Max scaling.
- Split data into training and
Once the data preparation is completed, you must choose the OCC algorithm based on your data.
Step 2 Choose an Algorithm
- One-class SVM- is great for small to medium datasets with clear boundaries.
- Isolation Forest- Ideal for high dimensional or sparse anomalies.
- Autoencoders- Best for complex data like images or sequences.
After choosing the algorithm perfect for your choice, now is time to train the model,
Step 3 Train the Model
Here’s an example of training a One-Class SVM for anomaly detection:
import numpy as np
from sklearn.svm import OneClassSVM
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
#Normal training data
np.random.seed(42)
normal_data = 0.3 * np.random.randn(100, 2)
#Scaling the data
scaler = StandardScaler()
normal_data_scaled = scaler.fit_transform(normal_data)
# Train OC-SVM
model = OneClassSVM(kernel="rbf", gamma=0.1, nu=0.05)
model.fit(normal_data_scaled)
#Predict on test data
test_data = scaler.transform([[0.1, 0.2], [-3, 3]])
predictions = model.predict(test_data)
#Visualization
plt.scatter(normal_data_scaled[:, 0], normal_data_scaled[:, 1], label="Normal Data", alpha=0.7)
plt.scatter(test_data[:, 0], test_data[:, 1], c=["green" if p == 1 else "red" for p in predictions],
label="Test Data (Green: Normal, Red: Anomaly)", edgecolor="black", s=100)
plt.title("One-Class SVM Example")
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.legend()
plt.grid()
plt.show()
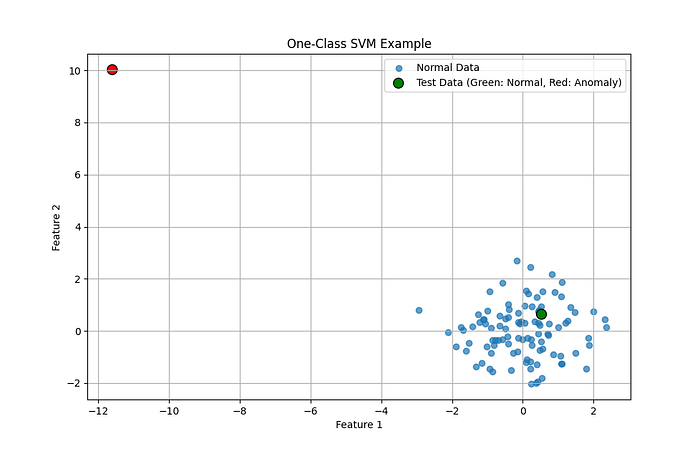
After training, the final step is to evaluate and deploy the model.
Step 4 Evaluate and Deploy
- When the model is trained, evaluating it using metrics like Precision, Recall, and F1-Score is essential. Based on the evaluation, adjust hyperparameters (like kernel, gamma, and nu) to optimize performance.
- Save the trained model using a library like Pickle or Joblib. Deploy the model into your application for real-time or batch anomaly detection.
- Continuously monitor the model for data drift and refrain as necessary to adapt to evolving patterns.
Conclusion
Through my exploration of One-Class Classifiers (OCCs), I gained insights into their importance in anomaly detection. These models have proven instrumental in addressing challenges across diverse domains such as cybersecurity, healthcare, and image analysis.
In my research, OCCs were critical in detecting anomalies in real-world scenarios. I effectively trained systems to detect anomalies by leveraging models like One-Class SVM and Autoencoders. This experience honed my understanding of OCCs and demonstrated their adaptability and effectiveness in handling dynamic and imbalanced datasets.
As anomaly detection continues to grow in importance, mastering OCCs equips us with a powerful toolkit for tackling real-world challenges. Thus, they are an essential component in the machine learning toolbox.